A specific subject that I’ve personally been getting interested in a lot lately is “computational neuroscience“, or basically, the connection between how your brain works and how the current generation of artificial intelligence (specifically, transformer based LLMs) work. My interest in this topic was spurred after I watched some videos created by the extremely under-viewed YouTuber Artem Kirsanov, in particular his video The Modular Architecture of Intelligence. In this video, Kirsanov details findings from a recent publication in Nature: “Building compositional tasks with shared neural subspaces“. The paper’s core finding: the brain will reuse subspaces of neural activity instead of completely building new representations from scratch (that’s a dense sentence, Kirsanov does an infinitely better job describing it in his video), is probably more interesting to neuroscientists, however, the paper’s description of how information is actually structured and stored in the brain immediately piqued my interest due to how familiar it seemed to the way concepts are “stored” in transformers (transformers are the primary component that make up model “AI” architecture).
In the paper, researchers described concepts like “color” and “shape” as being represented as regions within a very high-dimensional neural-space where a single point represents the combined electrical activity of all the neurons making up the space (for example, 100 neurons = 100 dimensional neural-space). The “color” and “shape” regions in this space can be thought of as a linearly separable cloud of points (for example, each trial where the monkey processes a specific colored object would add a point, and all those points cluster into a region or “cloud” of color points — same idea for shape points), meaning the concepts don’t bleed into each other, they occupy distinctive territory. This concept is proven in the paper as the scientists train a linear classifier on the neural activations (points) within the neural-space and were able to accurately determine which concept and category (i.e., they knew the monkey was thinking about color and specifically the color red) the monkey was perceiving given the positions of these points. Honestly that in itself blew my mind.
Here are some pictures from the aforementioned video and paper describing the points I made above:
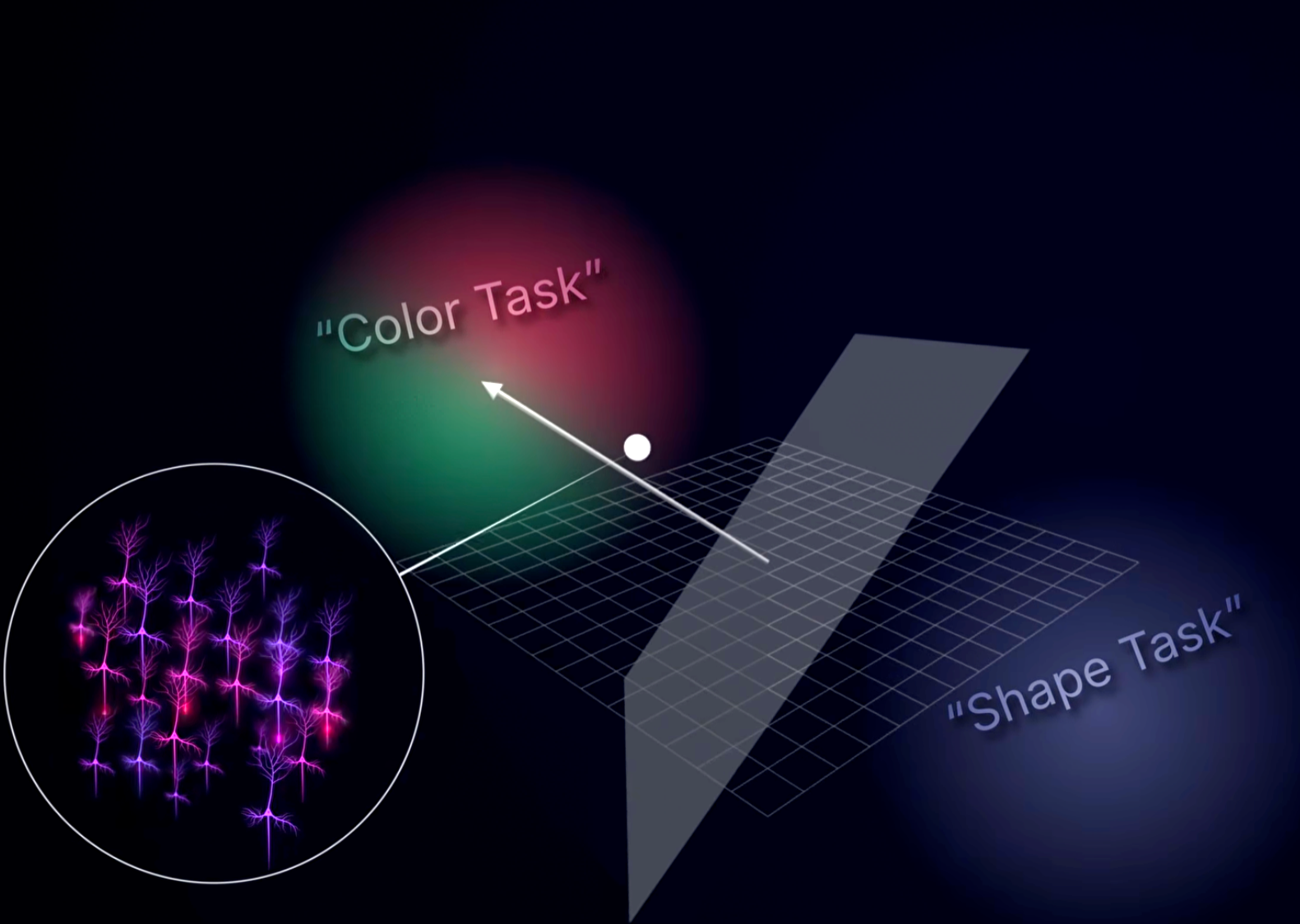
Credit: Artem Kirsanov
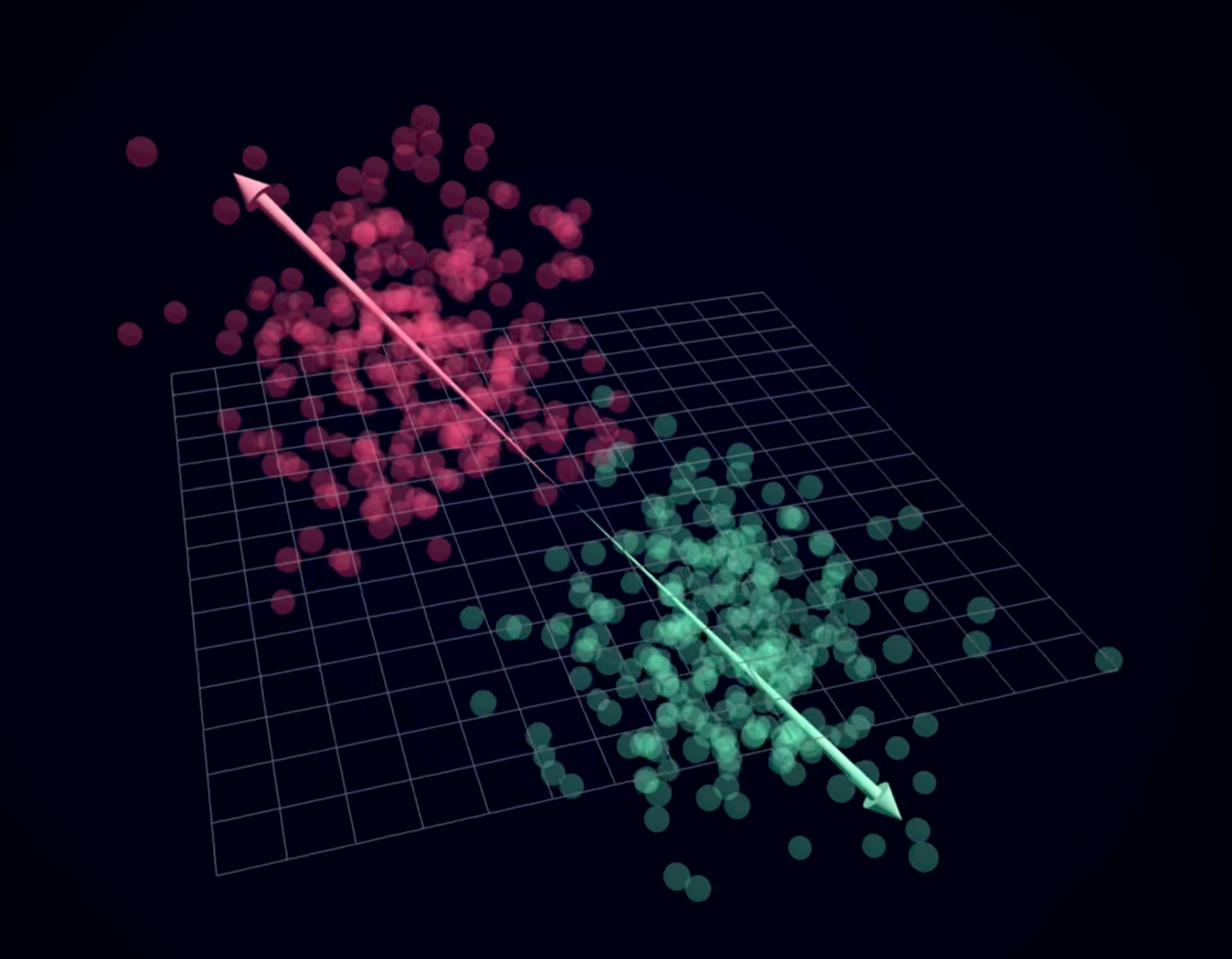
Credit: Artem Kirsanov
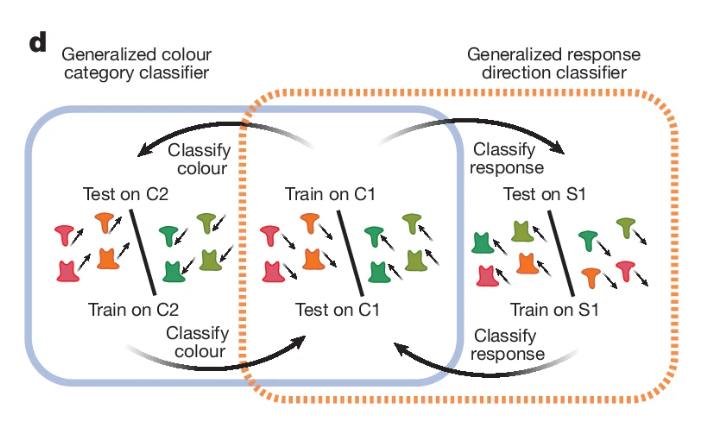
Credit: Figure 2 from Tafazoli et al. (2026), Nature
However, what I found to be the most interesting part of this exploration was the seemingly very direct connection to how concepts are represented in today’s large language model (LLM) based AI. If we look into the current research on how LLMs, specifically LLMs with transformer architecture (1), store concepts – we see some parallels to the monkey brain experiment described above. In LLMs, “concepts” are represented as directions (think about the linear classifier used in the monkey experiment pointing to directions of neural-space) within the high dimensional space (this of the neural-space described above!) the residual stream of data that makes up part of the model occupies. To make that sound less conceptual, basically, an AI (LLM) model is encoding concepts in a very high dimensional (AKA, a very long list) vector/list of numbers where each number is a dimension (for the GPT3 family, which was the first ChatGPT public model, it was 12,288 dimensions, aka an embedding space of 12,288) where, for ease of explanation, each dimension can be thought of as an individual concept. **However in practice, concepts would be stored across many dimensions at once instead of simply being tied to a single dimension and sometimes concepts can actually overlap the same dimensions (this is known as superposition within LLMs).** The latest state of the art models have far more dimensions in their residual stream, however, the exact numbers are not public – but the idea is they can represent more and more concepts given that there’s more space to fit them. The topic of figuring out how and what exactly each dimension means in human understandable terms is a very active area of research known as mechanistic interpretability, and leads to a likely impossible question to answer: How do LLMs actually store information and how does it represent that information within its neural activations? However, the problem remains – both transformers and the brain, for now, are almost complete black boxes that we have an extremely limited view into.
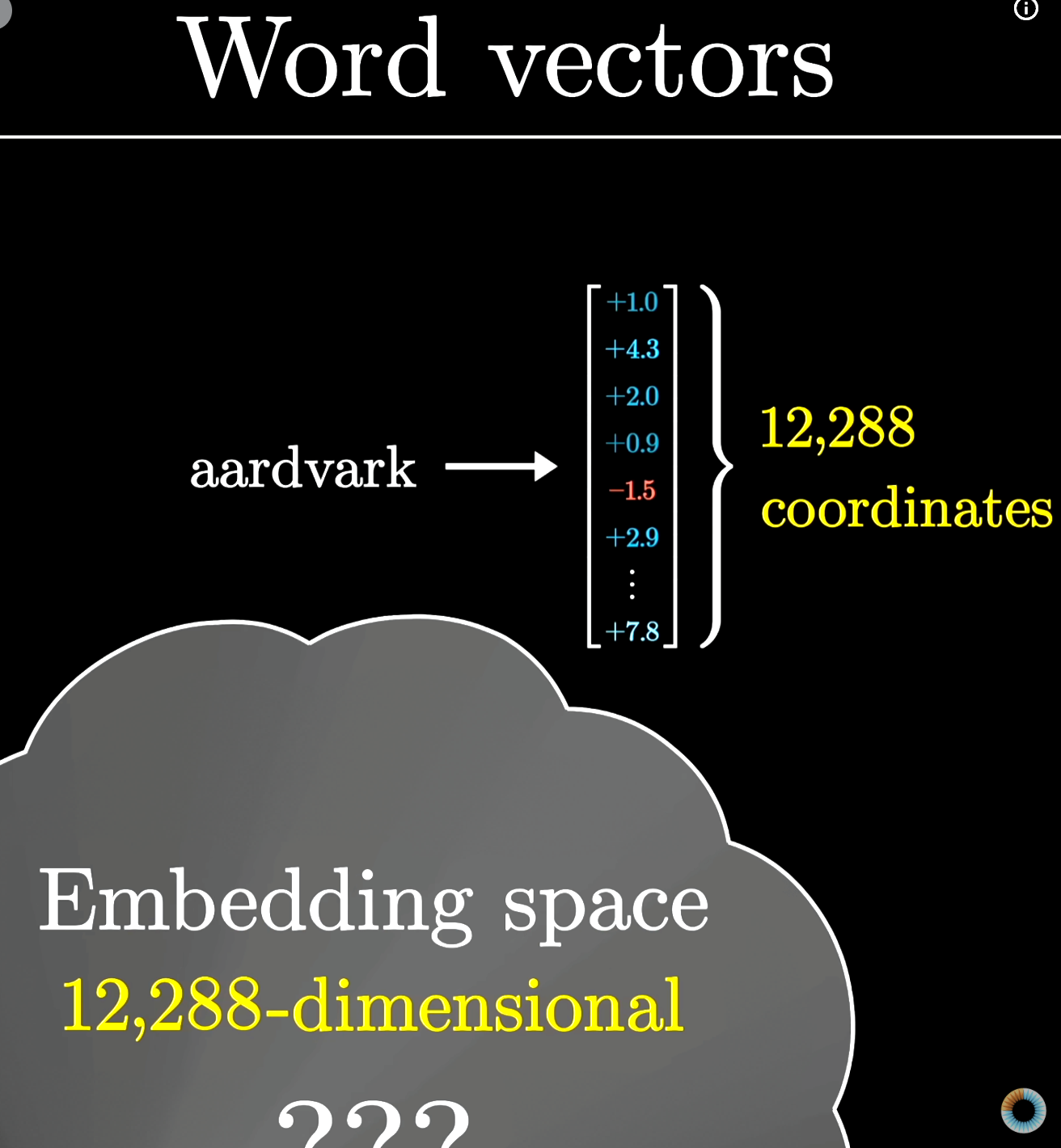
(Aside: For some reading and videos on this idea I presented, I’d check out these papers: Linguistic Regularities in Continuous Space Word Representations, Toy Models of Superposition – and a more intuitive video from which the picture below is from: Transformers, the tech behind LLMs | Deep Learning Chapter 5) – all of this is extremely interesting to read into but the video by 3Blue1Brown is a great visual and intuitive explanation of concept representation in transformers.